学习 xgboost
久闻 xgboost 大名,一直没有去了解。最近工作要用到,我打算了解一下。现在我对它没有任何概念。。
疑问
- 分类树、回归树分别是什么,有什么区别
References
https://machinelearningmastery.com/gentle-introduction-xgboost-applied-machine-learning/
https://www.cnblogs.com/ModifyRong/p/7744987.html
https://cloud.tencent.com/developer/article/1005611
https://www.cnblogs.com/pinard/p/6140514.html
https://xgboost.readthedocs.io/en/latest/model.html
https://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf
model: 给定 x 输出 y 的数学函数。
Objective function: model 确定,评价参数性能的函数。
- Training loss
Regularization
classification and regression trees (CART) simple and predictive: The tradeoff between the two is also referred as bias-variance tradeoff in machine learning.
So-called tree esamable model
What is actually used is the so-called tree ensemble model, which sums the prediction of multiple trees together.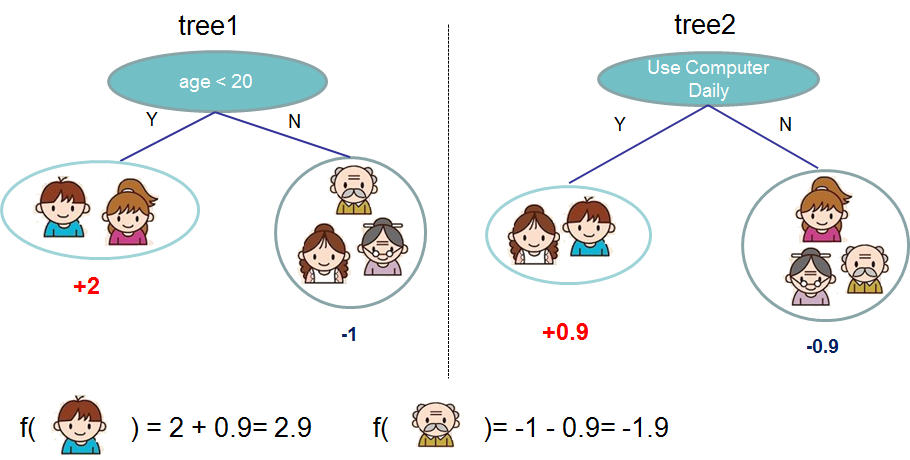
两个树之间的 complement each other.
random forest and boost tree
Now here comes the question, what is the model for random forests? It is exactly tree ensembles! So random forests and boosted trees are not different in terms of model, the difference is how we train them.
what is the model for random forests?
It is exactly tree ensembles!
Additive Training
Instead, we use an additive strategy: fix what we have learned, and add one new tree at a time.
只做加法处理,每次增加树的时候,只考虑当前树的损失和正则项,把之前训练得到的模型当作常量。(这个是不是上面说的“the difference is how we train them” ?)
第 t 棵树的损失函数:
questions
- For example, you should be able to describe the differences and commonalities between boosted trees and random forests.
This is how xgboost can support custom loss functions. 这个从 obj 到 custom loss funstions 这个过程并没有太明白。
gbdt
在 https://blog.csdn.net/w28971023/article/details/8240756 文章里面,提到
残差向量(-1, 1, -1, 1)都是它的全局最优方向
这个确实之前没有想到过。
这样理解的话,每个树,都是在原有树(或者一个组合的基础上)再优化(指向最优方向),而不是每个树都在做相同的优化,做重复的工作。这样貌似可以每个树有一个专一的优化方向,而不用每个树都胡子眉毛一把抓。。。
boosting & bagging
Boosting: 利用预测值与期望值之间的差别(residual)得到新的期望值,利用新的期望值和特征再训练新的模型,所以 boosting 每次都要用到所有的数据。 Bagging: 利用样本采样和特征采样的方式,让多个决策器学习样本的不同部分的不同特征,进而获得全局决策的方案。
相同的相思:利用多个分类器,学习不同的部分(可以是对样本、特征或者期望值细节描述的差异)。
番外

缺点是,它只能按照坐标轴划分,不能有斜线,不能有曲线。
如果要实现相同的斜线或者曲线,需要非常复杂的划分。看上图。
kaggle 中学习 xgboost
https://www.kaggle.com/dansbecker/learning-to-use-xgboost/code
xgboost.DMatrix
http://xgboost.readthedocs.io/en/latest/python/python_api.html#xgboost.DMatrix
class xgboost.DMatrix(data, label=None, missing=None, weight=None, silent=False, feature_names=None, feature_types=None, nthread=None)
Bases: object
Data Matrix used in XGBoost.
DMatrix is a internal data structure that used by XGBoost which is optimized for both memory efficiency and training speed. You can construct DMatrix from numpy.arrays
Parameters:
data (string/numpy array/scipy.sparse/pd.DataFrame) – Data source of DMatrix. When data is string type, it represents the path libsvm format txt file, or binary file that xgboost can read from.
label (list or numpy 1-D array, optional) – Label of the training data.
missing (float, optional) – Value in the data which needs to be present as a missing value. If None, defaults to np.nan.
weight (list or numpy 1-D array , optional) – Weight for each instance.
silent (boolean, optional) – Whether print messages during construction
feature_names (list, optional) – Set names for features.
feature_types (list, optional) – Set types for features.